把每一个字符绘制到一个小的区域中, 然后计算整个区域中的灰白比例, 得到对应的一个参数, 按参数排列得到一个字符按疏密排序后的列表.
import Image, ImageDraw, ImageFont
from itertools import product
def get_data_list():
fontpath = '/usr/share/fonts/TTF/DejaVuSansMono.ttf'
fontsize = 20
h = 24
w = int(h*0.618)
charlist = r'''0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ`~!@#$%^&*()-_=+[{]}\|;:'",<.>/?'''
def get_char_data(c):
im = Image.new('L',(w, h),255)
draw = ImageDraw.Draw(im)
font = ImageFont.truetype(fontpath, fontsize)
draw.text((0,0), c, font = font)
#im.show()
ans = 0.0
for i, j in product(range(w), range(h)):
ans += im.getpixel((i,j))
return ans / (255.0 * w * h)
lst = map(lambda c: [c, get_char_data(c)], charlist)
lst.sort(key=lambda i: i[1])
return lst
然后把要转换的图片转成灰度, 因为每个字符的宽长比大约是1/2, 所以图片的宽度要先伸展2倍, 然后缩小的一个需要的大小, 用每个像素的灰度值索引到之前算出的列表中的相应字符, 输出即可.
import Image
from pre import get_data_list
from itertools import product
clst = get_data_list()
im = Image.open('stevejobs.png')
size = list(im.size)
size[0]=size[0]/0.5
width = 70
size = (width,int(size[1]/size[0]*width))
im = im.resize(size)
im = im.convert('L')
#im.show()
fo = file('asciiart.txt','w')
for j in range(size[1]):
for i in range(size[0]):
idx = int( im.getpixel((i,j)) / 255.0 * (len(clst)-1) )
fo.write(clst[idx][0])
fo.write('\n')
fo.close()
效果图:
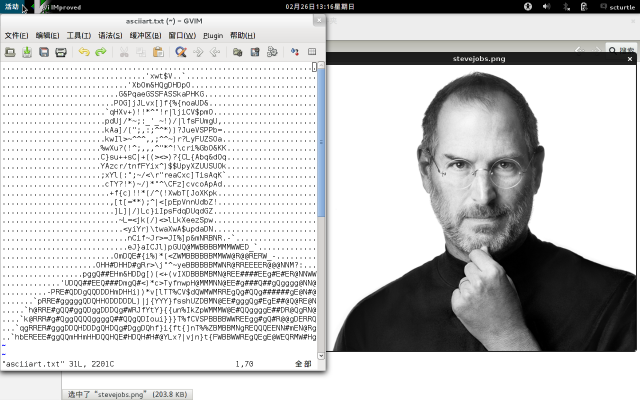
离远点看, 还是有点意思的~