查单词py脚本
2011年5月22日 10:45
改编自:http://www.oschina.net/code/snippet_70229_2366 加了终端颜色罢了
效果:
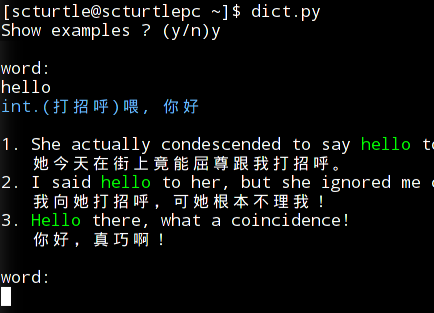
code:
#!/usr/bin/env python2
#coding=utf-8
import urllib,sys,re
#预编译正则式
re_def =re.compile(r'<def>(.*?)</def>', re.M|re.I|re.S|re.U)
re_sugg=re.compile(r'<sugg>(.*?)</sugg>', re.M|re.I|re.S|re.U)
re_orig=re.compile(r'<orig>(.*?)</orig>', re.M|re.I|re.S|re.U)
re_tran=re.compile(r'<trans>(.*?)</trans>', re.M|re.I|re.S|re.U)
#终端颜色
WARNING='\033[93m'
OKBLUE='\033[94m'
OKGREEN='\033[92m'
END = '\033[0m'
#是否输出例句
eg=True
def clear(s):
return s.replace('<em>',OKGREEN).replace('</em>',END)
def get(word):
ans = urllib.urlopen('http://dict.cn/ws.php?utf8=true&q=' + urllib.quote(word)).read()
try:
print OKBLUE+re_def.search(ans).group(1)+END
except:
suggs=re_sugg.findall(ans)
print WARNING+'suggest:'+END
for w in suggs: print w
return
if eg:
origs=re_orig.findall(ans)
trans=re_tran.findall(ans)
for i in range(len(origs)):
print "%d. %s"%(i+1,clear(origs[i]))
print "%s %s"%(' '*((i+1)/10+1),clear(trans[i]))
if __name__ == '__main__':
eg= raw_input('Show examples ? (y/n)')=='y'
while True:
try:
word=raw_input('\nword:\n')
except EOFError: break
get(word)