用FF的cookie获得豆瓣FM加心歌曲列表
2011年8月04日 17:00
update at 2012.2.29: 传送门 to isnowfy大牛的方法
受这篇文章启发将firefox的cookie转换为python可用的cookie_jar对象,然后就可以伪装为已登录了,不用再搞什么模拟post了!cookie万岁!
把以前的代码改了改果断又可用了,需要安装BeautifulSoup和pysqlite两个python包,需要输入共有多少页:
update at 2012.2.29: 传送门 to isnowfy大牛的方法
受这篇文章启发将firefox的cookie转换为python可用的cookie_jar对象,然后就可以伪装为已登录了,不用再搞什么模拟post了!cookie万岁!
把以前的代码改了改果断又可用了,需要安装BeautifulSoup和pysqlite两个python包,需要输入共有多少页:
如果想绕过django的后台数据库实现第三方认证的登陆,就要重写一个处理验证的后端了:
from django.contrib.auth.models import User
class MyCustomBackend:
def authenticate(self, username=None, password=None):
if True:
try:
user = User.objects.get(username=username)
except User.DoesNotExist:
user = User(username=username, password='')
#user.is_staff = True
#user.is_superuser = True
user.save()
return user
return None
def get_user(self, user_id):
try:
return User.objects.get(pk=user_id)
except User.DoesNotExist:
return None
然后在settings.py中加入:
AUTHENTICATION_BACKENDS = ( 'path.to.MyCustomBackend', )
以上便可以实现任意用户,任意密码登陆,不过还是不能完全摆脱django的User数据库的......
ref:
https://docs.djangoproject.com/en/dev/topics/auth/#handling-authorization-in-custom-backends
http://www.djangorocks.com/tutorials/creating-a-custom-authentication-backend.html
改编自:http://www.oschina.net/code/snippet_70229_2366 加了终端颜色罢了
效果:
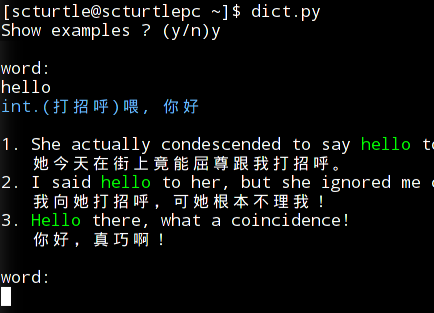
code:
#!/usr/bin/env python2
#coding=utf-8
import urllib,sys,re
#预编译正则式
re_def =re.compile(r'<def>(.*?)</def>', re.M|re.I|re.S|re.U)
re_sugg=re.compile(r'<sugg>(.*?)</sugg>', re.M|re.I|re.S|re.U)
re_orig=re.compile(r'<orig>(.*?)</orig>', re.M|re.I|re.S|re.U)
re_tran=re.compile(r'<trans>(.*?)</trans>', re.M|re.I|re.S|re.U)
#终端颜色
WARNING='\033[93m'
OKBLUE='\033[94m'
OKGREEN='\033[92m'
END = '\033[0m'
#是否输出例句
eg=True
def clear(s):
return s.replace('<em>',OKGREEN).replace('</em>',END)
def get(word):
ans = urllib.urlopen('http://dict.cn/ws.php?utf8=true&q=' + urllib.quote(word)).read()
try:
print OKBLUE+re_def.search(ans).group(1)+END
except:
suggs=re_sugg.findall(ans)
print WARNING+'suggest:'+END
for w in suggs: print w
return
if eg:
origs=re_orig.findall(ans)
trans=re_tran.findall(ans)
for i in range(len(origs)):
print "%d. %s"%(i+1,clear(origs[i]))
print "%s %s"%(' '*((i+1)/10+1),clear(trans[i]))
if __name__ == '__main__':
eg= raw_input('Show examples ? (y/n)')=='y'
while True:
try:
word=raw_input('\nword:\n')
except EOFError: break
get(word)
updated at 2012.10.8:https://github.com/scturtle/zhseg
昨天的算法课老师以中文分词为例讲了DP,换了种简单的方式(求分词后频率和最大)实现了一下,效果不错,频率词典是从这里找的: http://download.csdn.net/source/347899 ,实测词典放到dict里后占了18MB内存
DP原理是令p[i]为s[i : n-1]的最优解,初始化为p[n]=0,转移公式为:
p[i]=max( freq(s[i : i+k-1] ) + p[i+k] ) 1<=k<=n-i
代码如下:
update at 2011.5.12: 使用了defaultdict简化了代码
# coding: utf-8
import collections
d=collections.defaultdict(lambda:0)
def init(dictfile):
f=open(dictfile,'r')
while 1:
line=f.readline()
if not line: break
word, freq = line.split('\t')
d[word.decode('gbk')]=int(freq)
f.close()
def fenci(s):
l=len(s)
p=[0 for i in range(l+1)]
t=[1 for i in range(l)]
for i in range(l-1,-1,-1):
for k in range(1,l-i+1):
if(d[s[i:i+k]]+p[i+k] > p[i]):
p[i]=d[s[i:i+k]]+p[i+k]
t[i]=k
print 'sum:',p[0]
i=0
while i<l:
print s[i:i+t[i]].encode('utf8'), # 'gbk' for win
i=i+t[i]
if __name__ == '__main__':
init('dict.txt')
s="科学研究需要大量的资金但社会资源有限需要政府调控所以需要政府的限制"
s=s.decode('utf8')
fenci(s)
显示结果为:
sum: 33505 科学 研究 需要 大量 的 资金 但 社会 资源 有限 需要 政府 调控 所以 需要 政府 的 限制
顺便贴一个以前写的求拼音首字母的小脚本:
# coding: utf-8
a=[ i.decode('utf8').encode('gbk') for i in
['澳', '怖', '错', '堕', '贰', '咐', '过',
'祸', '祸', '骏', '阔', '络', '穆', '诺',
'沤', '瀑', '群', '弱', '所', '唾',
'唾', '唾', '误', '褕', '孕', '座',] ]
def firstpy(s):
s=s.encode('gbk')
i=0
while i<26 and a[i]<s:
i+=1
return '%c' % (97+i)
if __name__=='__main__':
s='判断字符串首字母'.decode('utf8')
for i in range(len(s)):
print firstpy(s[i]),